
Cloud Deplyed URL: http://ec2-18-119-103-98.us-east-2.compute.amazonaws.com/
Offl Project Repo: https://github.com/AI6002/capstone-project-team2
Contributors: https://github.com/AI6002/capstone-project-team2/graphs/contributors
Milestones: https://github.com/AI6002/capstone-project-team2/milestones
More About Group & Project Insights
About Us (Team of 3 people)
We are graduate students pursuing Masters in Artificial Intelligence (MAI) from Memorial University. We have developed this application for Our Capstone-MAI.
Insights: Having prior experience in Web-Application development and knowledge in Vision Models I got the opportunity to lead the group into the successful completion of the Project within 3 months short period of time.
Grade: 98 (Highest of the Batch)
The Project focuses on Developing Visual Question Answering (VQA) Chat application based on scene understanding, wherein the system must harness the synergy of computer vision, natural language processing, and commonsense knowledge to accurately respond to usergenerated questions related to visual content.Our proposed VQA system provides solution for Scene understanding for images that are captured around our outdoor or Indoor surroundings.
The VQA Model Used here is based on ViLT ICML 2021: Vision-and-Language Transformer Without Convolution or Region Supervision.
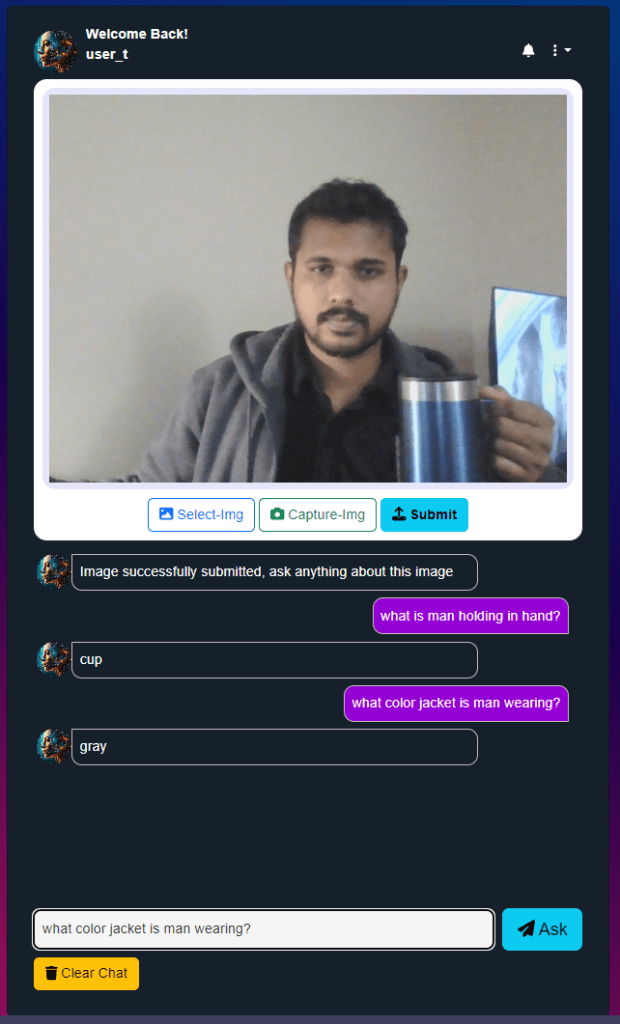
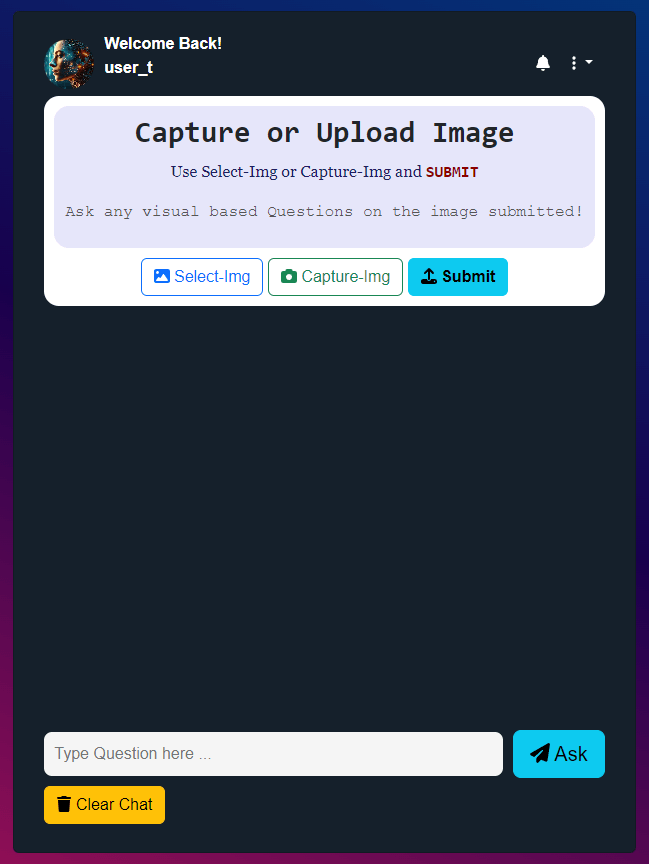
- The Question And Answering would be Chat User Interface.
- The Web-App can be used in Mobile phone or Desktop device via Browser.
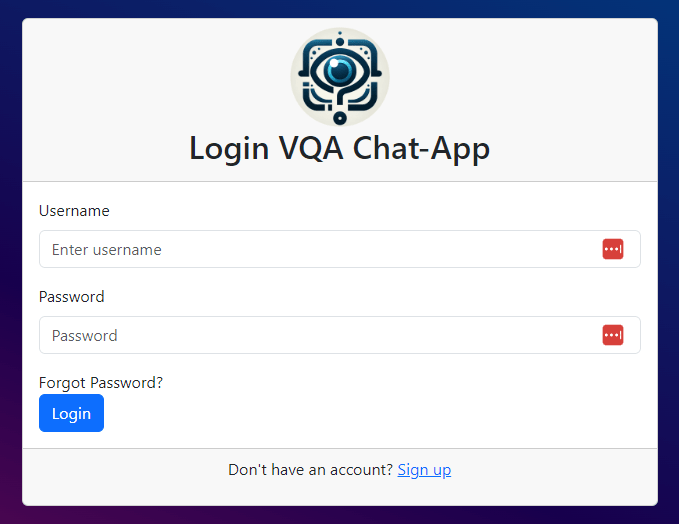
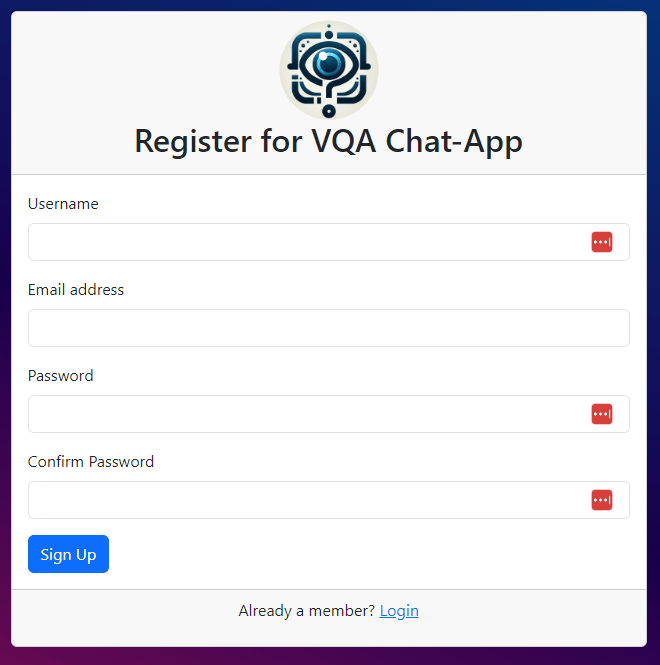
- Users can Sign-up and login into the VQA Chat-App.
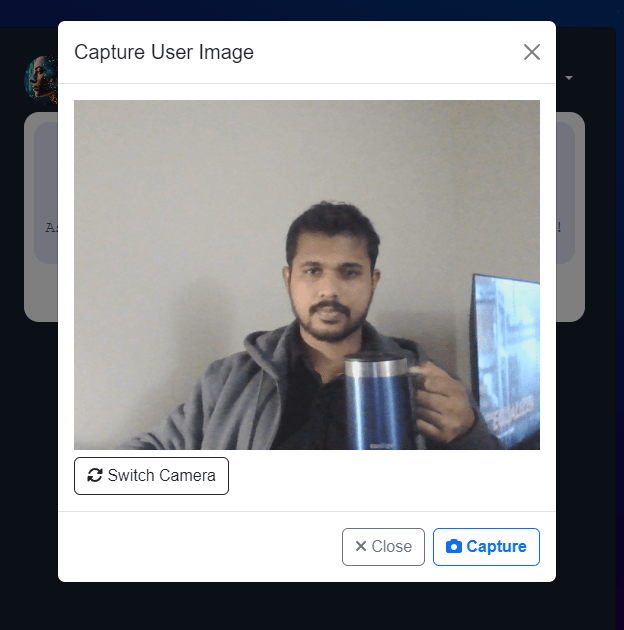
- UI allows the user to capture a photo using the camera or Upload a picture from device.
- App will Prompt for Question from the User about the Image.
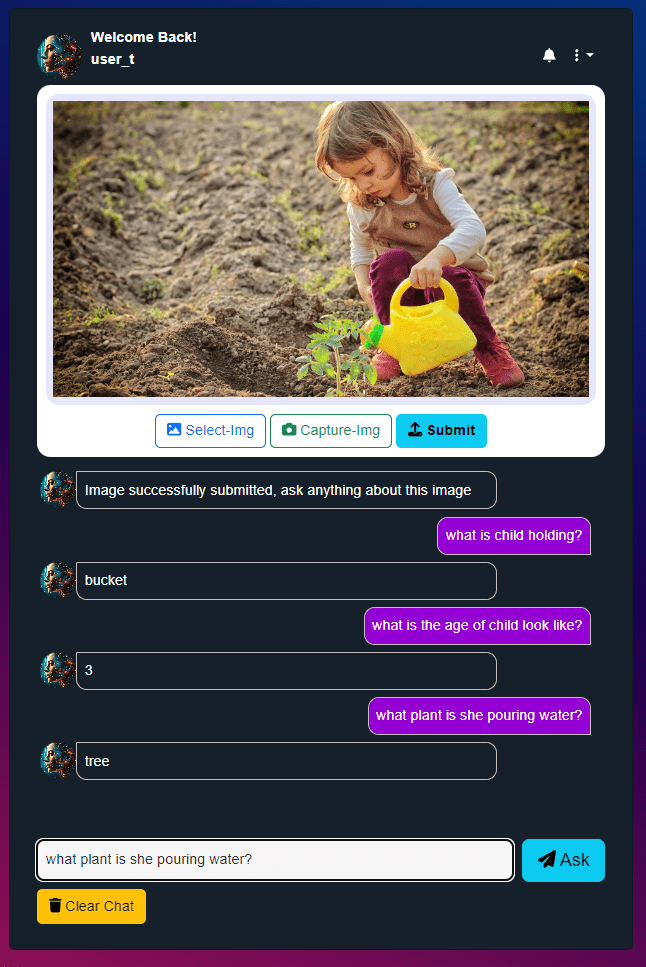
- User type in a question about the image’s visual content.
- System Responds with an Answer generated by the VQA Model and displayed as chat reply.
Key Aspects
Visual Understanding: The system should have the capability to analyze and comprehendthe content of images and videos, extracting relevant information about objects, people,actions, and spatial relationships.
Natural Language Processing: The application must be able to process and understandnatural language questions posed by users. This includes handling a variety of questiontypes, such as “What,” “Where,” “Why,” and “How.”
Commonsense Reasoning: The system should integrate a repository of commonsenseknowledge to enable it to answer questions that may not have explicit information in thevisual content. For instance, it should be able to infer answers to questions like “Why arethe men jumping?”, “What is the kid doing?”
VQA – A Multi-Modal Task
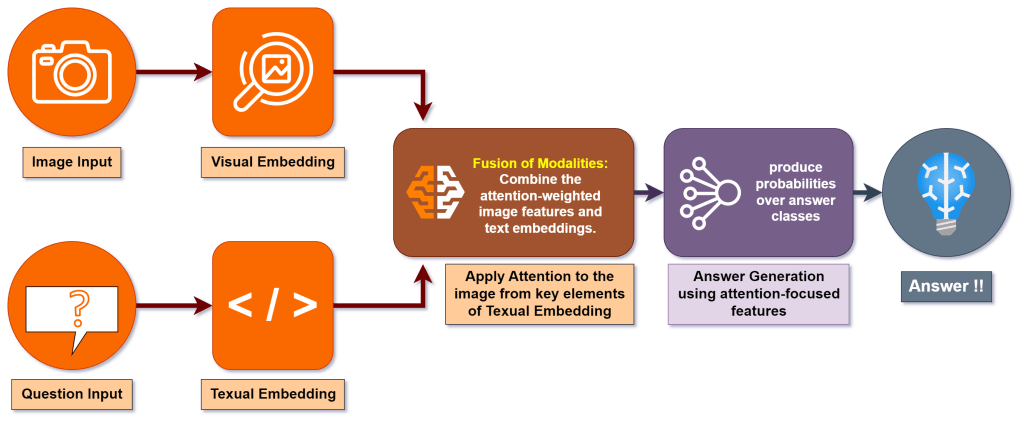
Architecture Overview
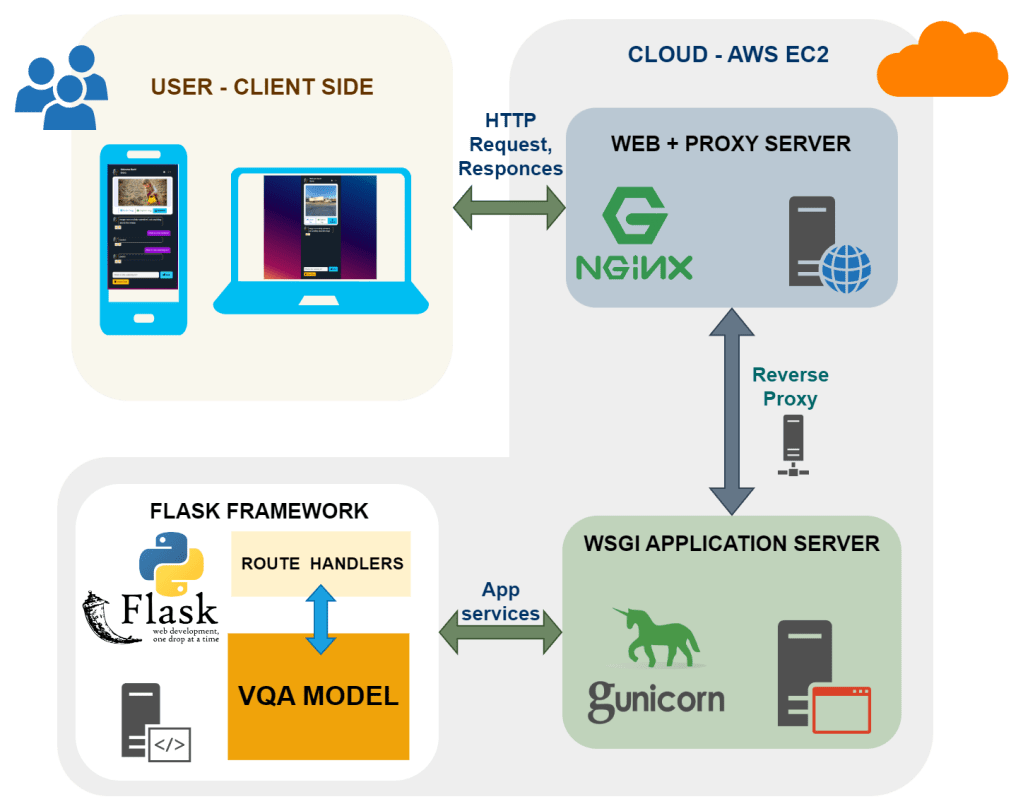
Screen-Shots of the VQA Chat App
Full Project Report
